【名古屋大学】相手の話を聞きながら話す、まるで人間のような対話 ~日本語で初のAI同時双方向対話モデル J-Moshiを開発~
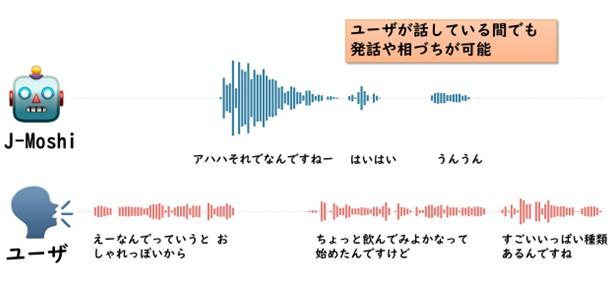
名古屋大学大学院情報学研究科の東中 竜一郎教授の研究グループは、相手の話を聞きながら話すことのできる、世界初の日本語で利用可能なFull-duplex音声対話モデル J-Moshiを開発しました。
本研究は、人間同士の対話における発話のオーバーラップや相づちなど、同時双方向的な対話を実現します。人工知能(AI)の音声対話性能を飛躍的に高め、まるで人間のような音声対話を実現します。雑談や接客など、さまざまな場面での利用が期待されます。
本研究成果は、2025年3月10日(月)-14日(金)に開催される、言語処理学会第31回年次大会(NLP2025)において発表されます。
本研究は、人間同士の対話における発話のオーバーラップや相づちなど、同時双方向的な対話を実現します。人工知能(AI)の音声対話性能を飛躍的に高め、まるで人間のような音声対話を実現します。雑談や接客など、さまざまな場面での利用が期待されます。
本研究成果は、2025年3月10日(月)-14日(金)に開催される、言語処理学会第31回年次大会(NLP2025)において発表されます。
【本研究のポイント】
・世界初の日本語で利用可能なFull-duplex(注1)音声対話モデル J-Moshi(注2)を開発。
・発話のオーバーラップ(重なり)や相づちなど、同時双方向的な対話を実現。
・大量の日本語音声対話データを用いた学習によって構築。
・世界初の日本語で利用可能なFull-duplex(注1)音声対話モデル J-Moshi(注2)を開発。
・発話のオーバーラップ(重なり)や相づちなど、同時双方向的な対話を実現。
・大量の日本語音声対話データを用いた学習によって構築。
【研究背景と内容】
人間同士の対話における発話のオーバーラップや相づちなど、同時双方向的な特徴をモデル化できるFull-duplex音声対話システムは、近年注目を集めています。しかし、日本語においてこうした音声対話システムはほとんど見られず、開発に関する知見が不足しています。本研究では、英語における主要なFull-duplex音声対話システムであるMoshiをベースとすることで、日本語で利用可能な最初のFull-duplex音声対話システムJ-Moshiを試作し、公開しました。
J-Moshiは、英語における7Bパラメータ(注3)のMoshiをベースとし、日本語の音声対話データでの追加学習によって構築されました。人間同士の対話におけるような自然なターンテイキングをリアルタイムに実現します。
人間同士の対話における発話のオーバーラップや相づちなど、同時双方向的な特徴をモデル化できるFull-duplex音声対話システムは、近年注目を集めています。しかし、日本語においてこうした音声対話システムはほとんど見られず、開発に関する知見が不足しています。本研究では、英語における主要なFull-duplex音声対話システムであるMoshiをベースとすることで、日本語で利用可能な最初のFull-duplex音声対話システムJ-Moshiを試作し、公開しました。
J-Moshiは、英語における7Bパラメータ(注3)のMoshiをベースとし、日本語の音声対話データでの追加学習によって構築されました。人間同士の対話におけるような自然なターンテイキングをリアルタイムに実現します。
J-Moshiのサンプル音声は以下でご確認いただけます。
https://nu-dialogue.github.io/j-moshi/
【成果の意義】
本研究は、人間同士の対話のように相づちを打ったり、相手の発話にかぶさるように返答したりするような、同時双方向的な対話を実現します。人工知能の対話性能を飛躍的に高め、あたかも人間のように話すことが可能となる技術です。雑談や接客など、さまざまな場面での利用が期待されます。
本研究は、ムーンショット目標1「2050 年までに、人が身体、脳、空間、時間の制約から解放された社会を実現」(JPMJMS2011)の支援を受けました。
また、本研究では名古屋大学のスーパーコンピュータ「不老」を利用しました。
本研究は、人間同士の対話のように相づちを打ったり、相手の発話にかぶさるように返答したりするような、同時双方向的な対話を実現します。人工知能の対話性能を飛躍的に高め、あたかも人間のように話すことが可能となる技術です。雑談や接客など、さまざまな場面での利用が期待されます。
本研究は、ムーンショット目標1「2050 年までに、人が身体、脳、空間、時間の制約から解放された社会を実現」(JPMJMS2011)の支援を受けました。
また、本研究では名古屋大学のスーパーコンピュータ「不老」を利用しました。
【用語説明】
注1)Full-duplex:
対話において、発話のオーバーラップや相づちなどの同時双方向的な特徴を有すること。
注2)J-Moshi:
Moshiは、フランスのAI研究機関Kyutai が開発したFull-duplexを実現した英語の音声対話モデルで、J-Moshiはこれをベースとした日本語で利用可能なFull-duplex音声対話システム。
注3)7Bパラメータ:
J-Moshiはニューラルネットワークで実現されている。ニューラルネットワークの性能はパラメータの数で一般に表現され、J-Moshiは70億(7 Billion)のパラメータを持つ。近年の大規模言語モデルとしては比較的軽量なサイズであり、さまざまな場面での活用が可能。
【論文情報(学会発表)】
雑誌名: 言語処理学会第31回年次大会 発表論文集
論文タイトル: 日本語Full-duplex音声対話システムの試作
著者: 大橋厚元、飯塚慎也、姜菁菁、東中竜一郎(すべて名古屋大学関係者)
本件に関するお問い合わせ先
名古屋大学広報課
- TEL
- 052-558-9735
- FAX
- 052‐788-6272
- nu_research@t.mail.nagoya-u.ac.jp