【立教大学】AI分野における世界最高峰の国際会議「NeurIPS 2025」で論文採択~連想記憶モデルによる新たなTransformerの提案~
【研究の概要】
本研究では、AI研究で基盤となるTransformerモデルを拡張し、その性能をさらに高める新しい方法を発見しました。従来から知られていた連想記憶モデルとTransformerの理論的な結びつきを拡張することで、Transformerが抱える「ランク崩壊(情報の多様性が失われる現象)」という問題を解消できることを理論と実験の両面から示しました。さらに、追加の学習パラメータを一切導入することなく、Vision TransformerやGPTといった既存のモデルの性能を向上させられることも確認しました。
【背景】
ChatGPTをはじめとする大規模言語モデル、画像認識システムや音声合成AIなど、現代の多くの人工知能は Transformer と呼ばれる深層学習モデルに基づいています。その応用範囲の広さと高い性能により、Transformerは今日のAI開発に欠かせない存在です。しかし、なぜTransformerがこれほど優れているのか、またその特殊な構造にどのような本質的意味があるのかは、依然として大きな研究テーマとなっています。
この謎に迫るヒントの一つが、1970〜80年代に甘利俊一氏やJohn Hopfield氏らによって研究された連想記憶モデルです。連想記憶モデルの研究は長らく停滞していましたが、2010年代以降に記憶容量を飛躍的に拡張する方法が発見され、さらに2021年にはRamsauerらによって「大きな記憶容量を持つ連想記憶モデルは、Transformerの自己アテンションそのものに対応する」という驚くべき発見がなされました。2024年には、この分野への貢献によりHopfield氏がノーベル物理学賞を受賞し、改めて注目が集まっています。
【研究成果】
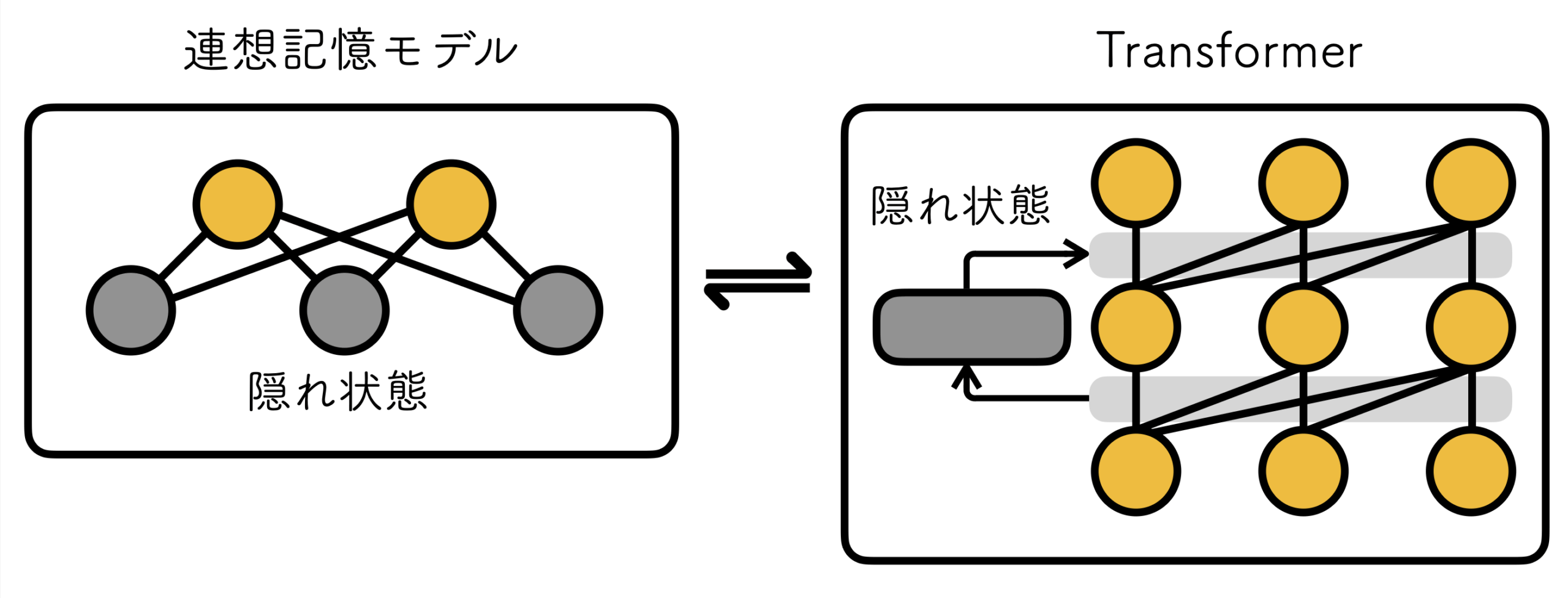
これまで知られていた連想記憶とTransformerの対応関係は、連想記憶モデルにおける「隠れ状態」を無視した近似に基づくものでした。私たちはこの隠れ状態に注目し、Transformerとの新たな対応関係を探りました。その結果、アテンションスコアの情報を層ごとに再帰的に伝える仕組みを備えた新しいTransformer を導入すると、連想記憶モデルとの関係を維持できることを発見しました。
さらに、この新しいTransformerは、従来の多層アテンションで起こる「ランク崩壊」を理論的にも実験的にも解消できることが分かりました。その結果、言語生成モデルや画像認識モデルに応用した場合、従来手法を超える性能が得られることを確認しました。特筆すべきは、追加の学習パラメータを一切導入せずに性能改善を実現できる点です。
【展望】
現在広く利用されているTransformerの性能向上には、これまで多くの場合トライアルアンドエラーに基づく経験的な工夫が用いられてきました。本研究は、こうしたTransformerの設計に対して、より深い理論的な指導原理を与える可能性を示しています。今後、連想記憶モデルに基づく理論を活用することで、より優れた生成AIの開発が進むことが期待されます。
■■ キーワード ■■
● 連想記憶モデル:断片的な情報だけから過去の完全な記憶を呼び出すことができる人工知能の基礎的なモデル
● 隠れ状態:連想記憶モデルの記憶と想起を助けるための補助的な変数
● Transformer:文章や画像などのデータを処理するために広く使われる深層学習モデル
● 自己アテンション:データの中で重要な部分同士の関係を見つけ出す仕組み
● Vision Transformer:画像認識にTransformerを応用したモデル
● GPT:文章を理解し生成する能力を持つ大規模言語モデル
● アテンションスコア:入力データの中でどの情報に注目するかを数値で表したもの
● ランク崩壊:Transformerの内部で、入力データのもつ情報の多様性が失われる現象
■■ 論文情報 ■■
●論文タイトル:On the Role of Hidden States of Modern Hopfield Network in Transformer
●著者:Tsubasa Masumura, Masato Taki
■■ 人工知能科学研究科 瀧雅人研究室について ■■
瀧雅人研究室では、これからのAIを支える深層学習に関して、基礎から応用まで幅広く研究しています。本成果以外にもAI・機械学習分野の国際会議「NeurIPS 2022」「CVPR 2024」に論文が採択されるなど、さまざまな成果を出しています。
本件に関するお問い合わせ先
立教学院企画部広報室
- koho@rikkyo.ac.jp